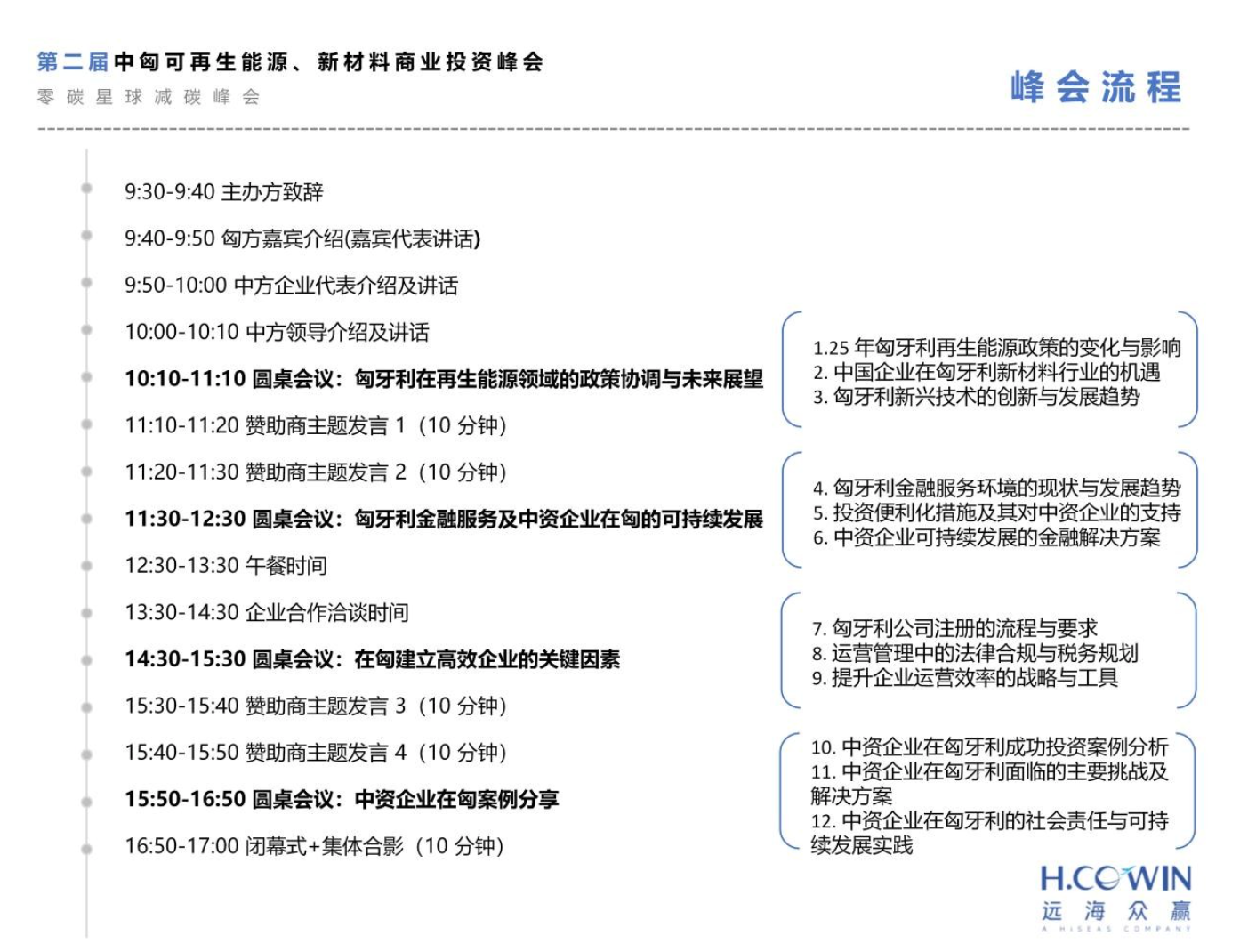
摘要:2024年6月3日,昆侖萬維宣布開源2千億稀疏大模型Skywork-MoE,性能強(qiáng)勁,同時推理成本更低。Skywork-MoE基于之前昆侖萬維開源的Skywork-13B模型中間checkpoint擴(kuò)展而來,是首個完整將MoEUpcycling技術(shù)應(yīng)用并落地的開源千億MoE大模型,也是首個支持用單臺4090服務(wù)器推理的開源千億MoE大模型。

2024年6月3日,昆侖萬維宣布開源 2 千億稀疏大模型 Skywork-MoE , 性能強(qiáng)勁, 同時推理成本更低。Skywork-MoE 基于之前昆侖萬維開源的 Skywork-13B 模型中間 checkpoint 擴(kuò)展而來,是首個完整將 MoE Upcycling 技術(shù)應(yīng)用并落地的開源千億 MoE大模型,也是首個支持用單臺 4090 服務(wù)器推理的開源千億 MoE大模型。
開源地址:
Skywork-MoE 的模型權(quán)重、技術(shù)報告完全開源,免費商用,無需申請:
? 模型權(quán)重下載:
? https://huggingface.co/Skywork/Skywork-MoE-base
? https://huggingface.co/Skywork/Skywork-MoE-Base-FP8
? 模型開源倉庫:https://github.com/SkyworkAI/Skywork-MoE
? 模型技術(shù)報告:https://github.com/SkyworkAI/Skywork-MoE/blob/main/skywork-moe-tech-report.pdf
? 模型推理代碼:(支持 8x4090 服務(wù)器上 8 bit 量化加載推理) https://github.com/SkyworkAI/vllm
模型架構(gòu):
本次開源的 Skywork-MoE 模型隸屬于天工 3.0 的研發(fā)模型系列,是其中的中檔大小模型(Skywork-MoE-Medium),模型的總參數(shù)量為 146B,激活參數(shù)量 22B,共有 16 個 Expert,每個 Expert 大小為 13B,每次激活其中的 2 個 Expert。
天工 3.0 還訓(xùn)練了 75B (Skywork-MoE-Small) 和 400B (Skywork-MoE-Large)兩檔 MoE 模型,并不在此次開源之列。
模型能力:
我們基于目前各大主流模型評測榜單評測了 Skywork-MoE,在相同的激活參數(shù)量 20B(推理計算量)下,Skywork-MoE 能力在行業(yè)前列,接近 70B 的 Dense 模型。使得模型的推理成本有近 3 倍的下降。同時 Skywork-MoE 的總參數(shù)大小比 DeepSeekV2 的總參數(shù)大小要小 1/3,用更小的參數(shù)規(guī)模做到了相近的能力。

技術(shù)創(chuàng)新:
為了解決 MoE 模型訓(xùn)練困難,泛化性能差的問題,相較于 Mixtral-MoE, Skywork-MoE 設(shè)計了兩種訓(xùn)練優(yōu)化算法:
1. Gating Logits 歸一化操作
我們在 Gating Layer 的 token 分發(fā)邏輯處新增了一個 normalization 操作,使得 Gating Layer 的參數(shù)學(xué)習(xí)更加趨向于被選中的 top-2 experts,增加 MoE 模型對于 top-2 的置信度:

2. 自適應(yīng)的 Aux Loss
有別于傳統(tǒng)的固定系數(shù)(固定超參)的 aux loss, 我們在 MoE 訓(xùn)練的不同階段讓模型自適應(yīng)的選擇合適的 aux loss 超參系數(shù),從而讓 Drop Token Rate 保持在合適的區(qū)間內(nèi),既能做到 expert 分發(fā)的平衡,又能讓 expert 學(xué)習(xí)具備差異化,從而提升模型整體的性能和泛化水平。在 MoE 訓(xùn)練的前期,由于參數(shù)學(xué)習(xí)不到位,導(dǎo)致 Drop Token Rate 太高(token 分布差異太大),此時需要較大的 aux loss 幫助 token load balance;在 MoE 訓(xùn)練的后期,我們希望 Expert 之間仍保證一定的區(qū)分度,避免 Gating 傾向為隨機(jī)分發(fā) Token,因此需要較低的 aux loss 降低糾偏。

訓(xùn)練 Infra
如何對 MoE 模型高效的進(jìn)行大規(guī)模分布式訓(xùn)練是一個有難度的挑戰(zhàn),目前社區(qū)還沒有一個最佳實踐。Skywork-MoE 提出了兩個重要的并行優(yōu)化設(shè)計,從而在千卡集群上實現(xiàn)了 MFU 38% 的訓(xùn)練吞吐,其中 MFU 以 22B 的激活參數(shù)計算理論計算量。
1. Expert Data Parallel
區(qū)別于 Megatron-LM 社區(qū)已有的 EP(Expert Parallel)和 ETP(Expert Tensor Parallel)設(shè)計,我們提出了一種稱之為 Expert Data Parallel 的并行設(shè)計方案,這種并行方案可以在 Expert 數(shù)量較小時仍能高效的切分模型,對 Expert 引入的 all2all 通信也可以最大程度的優(yōu)化和掩蓋。相較于 EP 對 GPU 數(shù)量的限制和 ETP 在千卡集群上的低效, EDP 可以較好的解決大規(guī)模分布式訓(xùn)練 MoE 的并行痛點,同時 EDP 的設(shè)計簡單、魯棒、易擴(kuò)展,可以較快的實現(xiàn)和驗證。

一個最簡單的 EDP 的例子,兩卡情況下 TP = 2, EP = 2, 其中 Attention 部分采用 Tensor Parallel , Expert 部分采用 Expert Parallel
2. 非均勻切分流水并行
由于 first stage 的 Embedding 計算和 last stage 的 Loss 計算,以及 Pipeline Buffer 的存在, 流水并行下均勻切分 Layer 時的各 stage 計算負(fù)載和顯存負(fù)載均有較明顯的不均衡情況。我們提出了非均勻的流水并行切分和重計算 Layer 分配方式,使得總體的計算/顯存負(fù)載更均衡,約有 10% 左右的端到端訓(xùn)練吞吐提升。

比較均勻切分和非均勻切分下的流水并行氣泡:對于一個 24 層 Layer 的 LLM, (a) 是均勻切分成 4 個 stage,每個 stage 的 layer 數(shù)量是:[6, 6, 6, 6].(b) 是經(jīng)過優(yōu)化后的非均勻切分方式,切成 5 個 stage, 每個 stage 的 layer 數(shù)量是:[5, 5, 5, 5, 4] , 在中間流水打滿的階段,非均勻切分的氣泡更低。
MoE Know-how
此外,Skywork-MoE 還通過一系列基于 Scaling Laws 的實驗,探究哪些約束會影響 Upcycling 和 From Scratch 訓(xùn)練 MoE 模型的好壞。

一個可以遵循的經(jīng)驗規(guī)則是:如果訓(xùn)練 MoE 模型的 FLOPs 是訓(xùn)練 Dense 模型的 2 倍以上,那么選擇 from Scratch 訓(xùn)練 MoE 會更好,否則的話,選擇 Upcycling 訓(xùn)練 MoE 可以明顯減少訓(xùn)練成本。
4090 推理
Skywork-MoE 是目前能在 8x4090 服務(wù)器上推理的最大的開源 MoE 模型。8x4090 服務(wù)器一共有 192GB 的 GPU 顯存,在 FP8 量化下(weight 占用 146GB),使用我們首創(chuàng)的非均勻 Tensor Parallel 并行推理方式,Skywork-MoE 可以在合適的 batch size 內(nèi)達(dá)到 2200 tokens/s 的吞吐。天工團(tuán)隊完整開源了相關(guān)的推理框架代碼和安裝環(huán)境,詳情參見:https://github.com/SkyworkAI/Skywork-MoE
結(jié)語
我們希望本次開源的 Skywork-MoE 模型、技術(shù)報告和相關(guān)的實驗結(jié)果可以給開源社區(qū)貢獻(xiàn)更多的 MoE 訓(xùn)練經(jīng)驗和 Know-how,包括模型結(jié)構(gòu)、超參選擇、訓(xùn)練技巧、訓(xùn)練推理加速等各方面, 探索用更低的訓(xùn)練推理成本訓(xùn)更大更強(qiáng)的模型,在通往 AGI 的道路上貢獻(xiàn)一點力量。

3月18日,昆侖萬維正式開源首款工業(yè)界多模態(tài)思維鏈推理模型Skywork R1V,即日起開源模型權(quán)重...
 2025-03-18
2025-03-18
2月18日,昆侖萬維開源中國首個面向AI短劇創(chuàng)作的視頻生成模型SkyReels-V1、中國首個SOT...
2025-02-18
2月14日,昆侖萬維正式推出 Matrix-Zero世界模型,成為中國第一家同時推出3D場景生成和可...
2025-02-14
今天,昆侖萬維正式推出具有復(fù)雜思考推理能力的系列模型——“天工大模型4.0” o1版(Skywork...
2024-11-27
從「天工大模型1.0」的研發(fā)到「天工大模型3.0」的發(fā)布,再到今天的「天工大模型4.0」階段,我們堅...
2024-11-20
天眼查專業(yè)版數(shù)據(jù)顯示,截至目前我國現(xiàn)存在業(yè)、存續(xù)狀態(tài)的物流運(yùn)輸相關(guān)企業(yè)約185.1萬家。
2025-02-17
天眼查專業(yè)版數(shù)據(jù)顯示,截至目前我國現(xiàn)存在業(yè)、存續(xù)狀態(tài)的家電相關(guān)企業(yè)超1983.4萬家。
2025-02-17
天眼查專業(yè)版數(shù)據(jù)顯示,截至目前我國現(xiàn)存在業(yè)、存續(xù)狀態(tài)的銀發(fā)經(jīng)濟(jì)相關(guān)企業(yè)超35.1萬家。
2025-02-17
天眼查專業(yè)版數(shù)據(jù)顯示,截至目前我國現(xiàn)存在業(yè)、存續(xù)狀態(tài)的黃金相關(guān)企業(yè)超14.5萬家。
2025-02-17
天眼查專業(yè)版數(shù)據(jù)顯示,截至目前我國現(xiàn)存在業(yè)、存續(xù)狀態(tài)的冰雪運(yùn)動相關(guān)企業(yè)超1.3萬家。
2025-02-17
天眼查專業(yè)版數(shù)據(jù)顯示,截至目前我國現(xiàn)存在業(yè)、存續(xù)狀態(tài)的冰雪運(yùn)動相關(guān)企業(yè)超1.3萬家。
2025-02-17
天眼查專業(yè)版數(shù)據(jù)顯示,包括人工智能、企業(yè)服務(wù)、光電、XR等行業(yè)在內(nèi),截至目前廣東省現(xiàn)存在業(yè)、存續(xù)狀態(tài)...
2025-02-17
天眼查專業(yè)版數(shù)據(jù)顯示,目前我國有動畫制作相關(guān)企業(yè)超18.3萬家,54.65%的相關(guān)企業(yè)成立于5~10...
2025-02-17
天眼查專業(yè)版數(shù)據(jù)顯示,截至目前我國現(xiàn)存在業(yè)、存續(xù)狀態(tài)的人工智能相關(guān)企業(yè)超403.3萬家。
2025-02-17
天眼查專業(yè)版數(shù)據(jù)顯示,截至目前我國現(xiàn)存在業(yè)、存續(xù)狀態(tài)的景區(qū)相關(guān)企業(yè)超46.1萬家。
2025-02-17投資家網(wǎng)(m.51baobao.cn)是國內(nèi)領(lǐng)先的資本與產(chǎn)業(yè)創(chuàng)新綜合服務(wù)平臺。為活躍于中國市場的VC/PE、上市公司、創(chuàng)業(yè)企業(yè)、地方政府等提供專業(yè)的第三方信息服務(wù),包括行業(yè)媒體、智庫服務(wù)、會議服務(wù)及生態(tài)服務(wù)。長按右側(cè)二維碼添加"投資哥"可與小編深入交流,并可加入微信群參與官方活動,趕快行動吧。








投資家網(wǎng)(http://m.51baobao.cn/)隸屬于北京微金科技有限公司,是國內(nèi)知名的資本與產(chǎn)業(yè)創(chuàng)新綜合服務(wù)平臺。平臺聚集數(shù)百萬優(yōu)秀創(chuàng)業(yè)者、資深PE/VC、投資銀行家、上市公司及實業(yè)高管、專家學(xué)者等,致力于構(gòu)建起資本、產(chǎn)業(yè)與政府之間的橋梁與生態(tài)服務(wù)體系。
郵箱:bp@wefinances.com
微信:yangqin6060
微信:15201337588






Copyright ? 投資家網(wǎng) | 京ICP備16014291號-1 | 京公安備11010502031933號網(wǎng)站地圖![]()

微博

微信公眾平臺