摘要:隨著京津冀、長三角、粵港澳大灣區、成渝等地啟動建設全國一體化算力網絡國家樞紐節點,“東數西算”工程全面正式啟動,作為數據處理的核心新型基礎設施,人工智能、物聯網、云計算、區塊鏈等技術將迎來更為精細化的發展前景。
隨著京津冀、長三角、粵港澳大灣區、成渝等地啟動建設全國一體化算力網絡國家樞紐節點,“東數西算”工程全面正式啟動,作為數據處理的核心新型基礎設施,人工智能、物聯網、云計算、區塊鏈等技術將迎來更為精細化的發展前景。近期,作為成渝地區東數西算的深度參與者,特斯聯對外公布了其計算機視覺(CV)領域的多個科研突破,并有8篇論文被CVPR、TPAMI等頂級國際學術會議和期刊收錄。
此次,特斯聯在 CV 領域的科研突破涵蓋了語義分割、圖像增強、顯著物體識別、遷移學習、行為識別,等方面。其中不少創新技術打破了現有技術上限,亦開發了數個性能更優、識別更快、效率更高的模型,這些技術研究的應用與推廣將會成為特斯聯賦能城市數字化、智能化的有力保障。
在機器視覺行業產業鏈中,如上游的光源、鏡頭、工業相機、圖像處理器、圖像采集卡等硬件,圖像處理軟件和底層算法等軟件系統會隨著機器視覺的迭代而快速發展,推進整個產業鏈的升級。全球知名AI專家、特斯聯集團首席科學家兼特斯聯國際總裁邵嶺博士及其團隊在該領域中提出的圖像和視頻的識別和學習各算法,極大縮短了訓練和推理時間,從圖像識別提升、識別效率提升以及解決數據標注瓶頸三個方面,提升了整體視覺應用效果:
1)圖像識別提升
在圖像識別方面,團隊的技術突破主要集中在算法層面,囊括背景消除模塊、圖像特征突出等。這些可以從圖像本質入手,豐富圖像本身信息,去除多余噪點,為后續圖像識別提供高清的圖像數據,是高效率識別的基礎。更有技術突破采用創新的手法,如加上聲音信息來協助識別,提高信息準確度。
在被收錄于頂會CVPR的《Learning Non-target Knowledge for Few-shot Semantic Segmentation》(《學習用于小樣本語義分割的非目標知識》)研究中,團隊從挖掘和排除非目標區域的新角度重新思考了少樣本語義分割,繼而提出了一個新穎的非目標區域消除(Non-target Region Eliminating)框架,其中包含了一個背景挖掘模塊(Background Mining Module)、一個背景消除模塊(Background Eliminating Module)和一個分散注意力的目標消除模塊(Distracting Objects Eliminating Module)以確保模型免受背景和分散注意力目標的干擾進而獲得準確的目標分割結果。不僅如此,該研究還提出一個原型對比學習(Prototypical Contrastive Learning)算法,通過精煉原型的嵌入特征以便更好的將目標對象與分散注意力的對象區分開來。

采用不同模塊的目標分割表現
在被收錄于TPAMI期刊的《Learning Enriched Features for Fast Image Restoration and Enhancement》(《學習用于快速圖像修復和增強的豐富特征》)研究中,團隊發現現實中的相機存在諸多物理限制,尤其在復雜的照明環境,采集的圖像經常會出現不同程度的退化現象。比如智能手機相機的光圈很窄,傳感器很小,動態范圍也有限,因而經常產生噪聲和低對比度的圖像。為此團隊提出了一種全新架構,其整體目標是通過整個網絡維持空間精確的高分辨率表征并從低分辨率表征中接收互補的上下文信息。 方法的核心囊括以下關鍵元素的多尺度殘差塊:(a) 用于提取多尺度特征的并行多分辨率卷積流,(b)跨多分辨率流的信息交換,(c)用于捕獲上下文信息的非局部注意力機制,(d)基于注意力的多尺度特征聚合。 該方法學習了一組豐富的特征,即結合了來自多個尺度的上下文信息,同時保留了高分辨率的空間細節。該技術可以解決現實中物理相機的缺陷,提高圖片質量,也為后續識別提供良好的載體。

采用我們所提出方法(下排右二)生成的圖像在視覺上更接近于亮度和整體對比度的地面真實情況
團隊還就顯著目標檢測(SOD)數據集的嚴重設計偏差問題進行了研究,并收集了一個全新高質量,目前最大的實例級SOD數據集- Salient Objects in Clutter(SOC),以縮小現有數據集與真實場景之間的差距。通過對203個代表性模型的回顧,和一個線上基準模型的維護,以及100個SOD模型全面的基準和性能評估,實現對SOD發展的動態追蹤以及更深入的理解。此外,團隊還設計了三個數據集增強策略,包括標簽平滑,隨機圖像增廣和基于自監督學習的正則化技術以有效提高尖端模型的效果。該技術可以在復雜環境中讓目標突出,在信息混亂的圖像或者視頻中,準確抓取目標,為識別分析提供準確信息。此研究成果被收錄于TPAMI期刊中。

與實例級ILSO數據集(a)和MS-COCO數據集(c)相比,我們的SOC數據集(b&d)可標注精細、平滑的邊界
由布景或攝像機視點變化引起的域偏移下的行為識別問題也是團隊重點研究的方向。在收錄于頂會CVPR中的《Audio-Adaptive Activity Recognition Across Video Domains》(《跨視頻域的音頻自適應行為識別》)的研究中,團隊提出了一種新穎的音頻自適應編碼器,借助豐富的聲音信息來調整視覺特征以便模型在目標域中學習更多的判別特征。 它通過引入一種音頻注入識別器(Audio-infused Recognizer)以進一步消除特定域(domain-specific)的特征,并利用聲音中的域不變信息來實現有效的跨域跨模態的交互。此外,還引入了一個actor shift的新任務,以及相應的數據集,以在行為外觀發生巨大變化的情況下挑戰該模型。該技術加入聲音參數來識別物體活動,可以更加準確識別和分析出物體的行為,在智慧城市應用中可以有更準確的分析結果。

當同一活動的視覺相似性在不同領域間難以發現時,我們的模型(紅色)可以使用來自聲音的額外線索來提高識別精度
基于自注意力的網絡在圖像描述取得了巨大成功但仍存在距離不敏感和低秩的瓶頸。為解決這一問題,團隊在發表于IEEE Transactions on Multimedia期刊中的《Multi-Branch Distance-Sensitive Self-Attention Network for Image Captioning》(《用于圖像描述的多分支距離敏感自注意力網絡》)研究中,對自注意力機制從兩個方面進行了優化:一個是距離敏感的自注意力方法(DSA),通過在SA建模過程中考慮圖像中目標之間的原始幾何距離,來提高圖像場景理解;另一個是多分支自注意力方法(MSA),以打破SA中存在的低秩瓶頸,并在可忽略的額外計算成本下提高MSA的表達能力。

我們的方法(下排)和標準Transformer模型(上排)生成的注意力可視化和圖像描述示例。一些準確的單詞用綠色標記,錯誤和不準確的單詞用紅色標記。我們的方法可得到更精確的描述。
2)識別效率提升
為提高識別效率,團隊研究出新的算法框架以及新的采樣器,可以顯著提高識別效率,大大縮短訓練時間。在圖像識別中,快速的識別可以提高服務質量,減少延遲,讓人們感受更智能的交互。
團隊發現大多數基于循環神經網絡的視頻物體分割(RVOS)方法采用基于單幀的空間粒度建模,而視覺表征的局限性容易導致視覺與語言匹配不佳。基于此,團隊提出一種新穎的多級表征學習方法,通過探索視頻內容的固有結構來提供一組視覺嵌入,從而實現更有效的視覺-語言語義對齊。具體來說,它在視覺粒度方面嵌入了不同的視覺線索,包括視頻級別的多幀長時信息、幀級別的幀內空間語義以及對象級別的增強對象感知特征。其次,它還引入了動態語義對齊(DSA),可以更緊湊、更有效地動態學習和匹配具有不同粒度視覺表征的語言語義。從實驗結果來看,該研究《Multi-Level Representation Learning with Semantic Alignment for Referring Video Object Segmentation》(《具有語義對齊的多級表征學習用于參考視頻對象分割》)具有較高的推理速度,也因此被頂會CVPR收錄。
在視覺研究中,團隊發現業界最流行的隨機采樣方法,PK采樣器,對深度度量學習來說信息量不足且效率不高,為此提出一種可用于大規模深度度量學習的高效的小批量采樣方法,稱為圖采樣(Graph Sampling)。該模型的思想是在每個epoch開始時為所有類別構建最近鄰關系圖。然后,每個小批量由隨機選擇的類別和其最近鄰組成以便學習信息豐富的示例。該方法顯著提高了重新識別率,大大縮短了訓練時間。該技術為通用技術,可用于圖像檢索、識別等。該技術主要目的是提升效率,這是在當下高負荷多信息的智慧領域必不可少的技術,快速分析識別能夠在一些圖像檢索和識別應用快速滿足用戶需求。該研究《Graph Sampling Based Deep Metric Learning for Generalizable Person Re-Identification》(《基于圖采樣的深度度量學習用于可泛化的行人重識別》)同樣收錄于今年的CVPR。
3)解決圖像標注問題
數據標注是一個重要的過程,傳統人工數據標注費時費力。團隊提出了一種新技術以更高效地解決背后的問題。該研究被收錄于今年的CVPR中,標題為《Category Contrast for Unsupervised Domain Adaptation in Visual Tasks》(《視覺任務中無監督域適應的類別對比》)。團隊提出了一種新的類別對比技術(CaCo),該技術在無監督域適應(UDA)任務的實例判別之上引入了語義先驗,可以有效地用于各種視覺UDA任務。該技術構建了一個具有語義感知的字典,其中包含來自源域和目標域的樣本,每個目標樣本根據源域樣本的類別先驗分配到一個(偽)類別標簽,以便學習與UDA目標完全匹配的類別區分但域不變的表征。與當下最先進的方法對比,簡單的CaCo技術可以實現更優越的性能表現,也可以成為現有UDA方法的補充,推廣到其他機器學習方法中去,如無監督模型適應,開放/部分集適應等。該技術解決了傳統監督學習需要大量人工標注的問題,比現有技術擁有更高的效率。




作為中國首倡并主辦的層級最高、規模最大的多邊外交活動,經過十年發展,“一帶一路”倡議已成為國際合作的...
 2023-10-19
2023-10-19
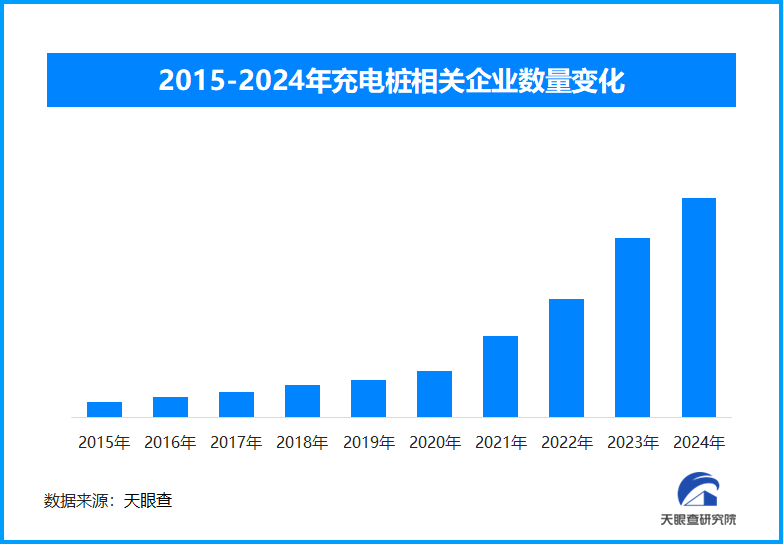
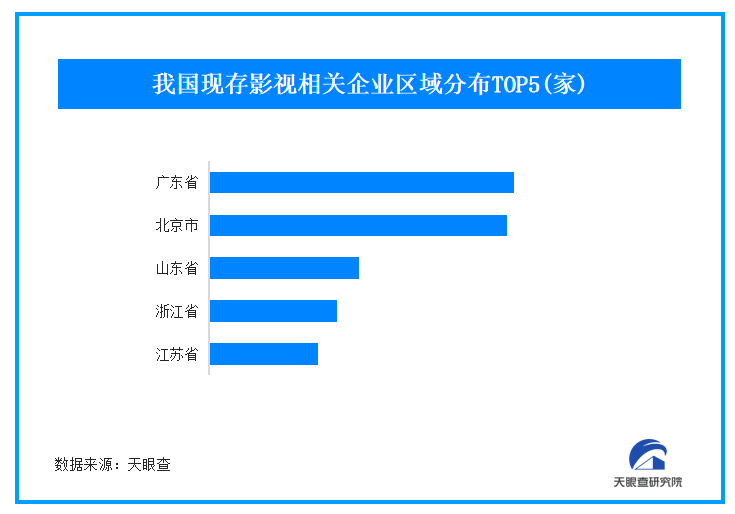
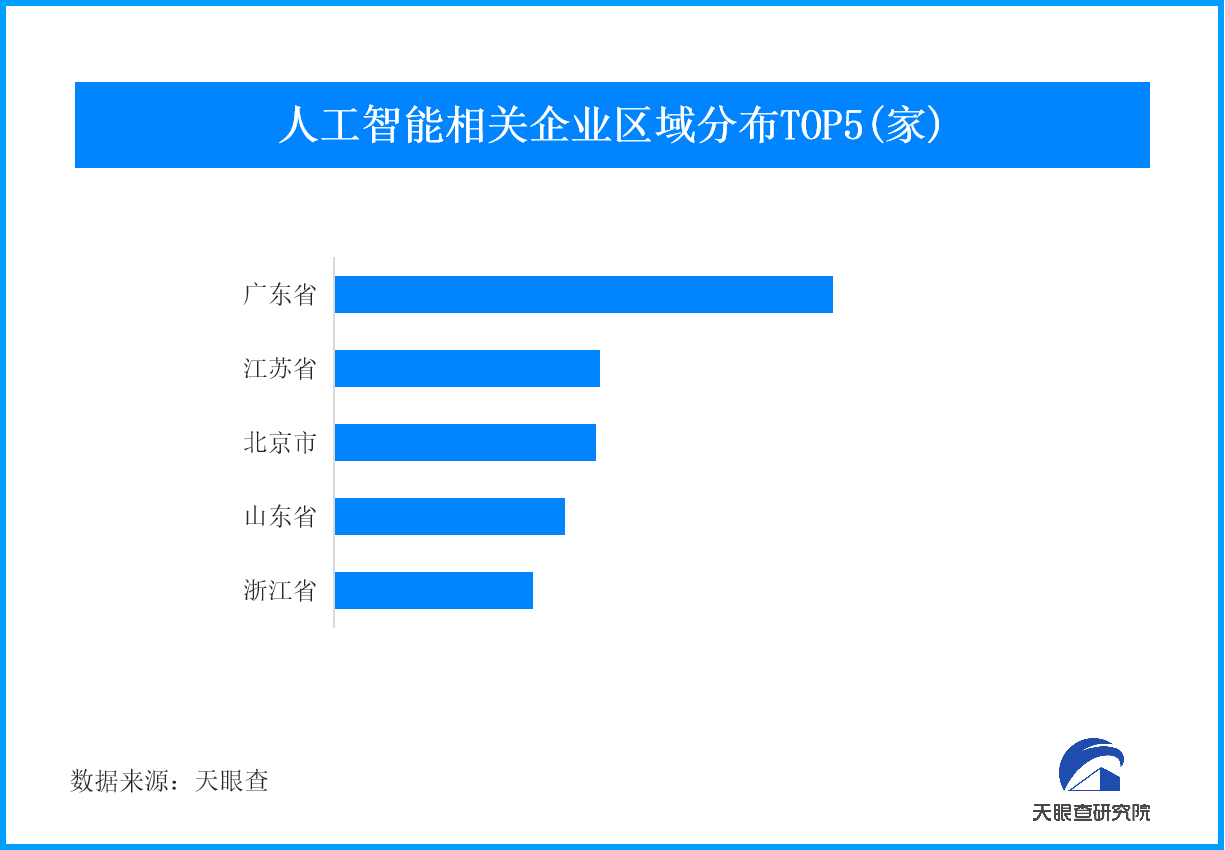
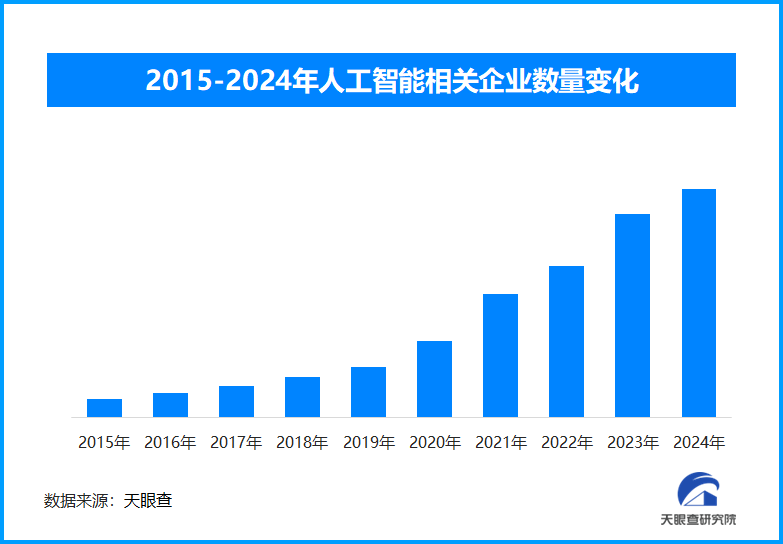
為填補這一巨大缺口,多方都在積極探索。高校紛紛增設AI相關專業課程,企業也加強與高校的產學研合作,加...
2025-02-24


投資家網(m.51baobao.cn)是國內領先的資本與產業創新綜合服務平臺。為活躍于中國市場的VC/PE、上市公司、創業企業、地方政府等提供專業的第三方信息服務,包括行業媒體、智庫服務、會議服務及生態服務。長按右側二維碼添加"投資哥"可與小編深入交流,并可加入微信群參與官方活動,趕快行動吧。






賽那德完成超億元B輪系列融資,提升裝卸貨機器人實力
申科譜獲超億元“B+輪”融資,加速產業發展
陜西麥科奧特醫藥完成超億元D輪融資,浙商創投領投


投資家網(http://m.51baobao.cn/)隸屬于北京微金科技有限公司,是國內知名的資本與產業創新綜合服務平臺。平臺聚集數百萬優秀創業者、資深PE/VC、投資銀行家、上市公司及實業高管、專家學者等,致力于構建起資本、產業與政府之間的橋梁與生態服務體系。
郵箱:bp@wefinances.com
微信:yangqin6060
微信:15201337588






Copyright ? 投資家網 | 京ICP備16014291號-1 | 京公安備11010502031933號網站地圖![]()

微博

微信公眾平臺